Centralizing Configuration with Spring Cloud Vault
28 Aug 2024What is Vault?
HashiCorp Vault is an identity-based secrets and encryption management system. A secret is anything that you want to tightly control access to, such as API encryption keys, passwords, and certificates. Vault provides encryption services that are gated by authentication and authorization methods. Using Vault’s UI, CLI, or HTTP API, access to secrets and other sensitive data can be securely stored and managed, tightly controlled (restricted), and auditable.

Configuration
Spring Cloud Vault accesses different resources. By default, the secret backend is enabled which accesses secret config settings via JSON endpoints.
In HashiCorp Vault, secrets are typically organized within the Key-Value (KV) secrets engine using paths. The structure of these paths can be designed to reflect the organization of your applications and environments. A common practice is to include the application name and the Spring profile (such as dev,test, prod) in the path to create a clear hierarchy and make it easy to manage secrets for different environments.
The HTTP service has resources in the form:
/secret/{application}/{profile}/secret/{application}/secret/{defaultContext}/{profile}/secret/{defaultContext}
where the “application” is injected as the spring.application.name in the SpringApplication (i.e. what is normally “application” in a regular Spring Boot app), “profile” is an active profile (or comma-separated list of properties). Properties retrieved from Vault will be used “as-is” without further prefixing of the property names.
Example:
secret/└── data/├── myapp/│ ├── dev/│ │ ├── username│ │ └── password│ ├── test/│ │ ├── username│ │ └── password└── anotherapp/├── dev/│ ├── apikey│ └── dbpassword└── test/├── apikey└── dbpassword
To use these features in an application, just build it as a Spring Boot application that depends on spring-cloud-vault-config :
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-vault-config</artifactId></dependency>
Here you configure your application with application.properties. The code below uses Spring Boot’s Config Data API which allows importing configuration from Vault:
spring.cloud.vault.kv.enabled=true spring.cloud.vault.authentication=TOKEN spring.cloud.vault.token=root-token #token from the vault server spring.cloud.vault.scheme=http spring.cloud.vault.host=127.0.0.1 spring.cloud.vault.port=8200
#mounts Vault as Property Source using all enabled secret backends spring.config.import=optional:vault://
in application.yml:
spring:cloud:vault:kv.enabled: trueauthentication: TOKENhost: 127.0.0.1port: 8200scheme: httptoken: root-token
#mounts Vault as Property Source using all enabled secret backends config: import: optional:vault://
How to Reference Secrets in Application Properties
Once you’ve configured Vault, you don’t directly reference the secrets in your application.properties or application.yml file. Instead, you use placeholders that correspond to the keys of the secrets stored in Vault. Spring Cloud Config will replace these placeholders with the actual values from Vault at runtime.
For example, if you have a username and password secret stored in Vault, you would reference them like this in your application.properties:
spring.datasource.username=${username}spring.datasource.password=${password}
Or in application.yml:
spring:datasource:username: ${username}password: ${password}
Our Preferred Approach
Introduction
Our preferred approach to managing configurations in Spring Boot applications leverages a combination of application names, client names, and Spring profiles to create a structured and scalable system for storing and retrieving secrets from HashiCorp Vault.
In Vault, we use a naming convention that concatenates the project name and client name, such as projectname-clientname, to form a unique identifier for each client within a project, which matches the spring application name. This convention simplifies the management of secrets by grouping them logically and reducing the complexity of path construction, where paths could be like logistic-internal-hornbach/staging.
In Spring boot project, We create a configuration file for each client (for ex: hornbach.yml ), Within each client’s configuration file, we define multiple profiles that correspond to different environments (e.g., staging, production), allowing us to switch between configurations effortlessly during deployment.
By setting environment variables like SPRING_CONFIG_LOCATION, SPRING_PROFILES_ACTIVE, and SPRING_APPLICATION_NAME, we ensure that the application knows where to find its configuration and which secrets to request from Vault, thus enabling a seamless integration with Vault’s centralized secret management.
Example
Consider the following environment variables:
SPRING_CONFIG_LOCATION=classpath:hornbach.ymlSPRING_PROFILES_ACTIVE=stagingSPRING_APPLICATION_NAME=logistic-internal-hornbach
Upon startup, Spring Boot will:
- Look for the hornbach.yml file in the classpath.
- Activate the staging profile.
- Construct the Vault path using the SPRING_APPLICATION_NAME and the active profile, resulting in secret/logistic-internal-hornbach/staging.
- Fetch the secrets from Vault and apply them to the application context.
HashiCorp Vault Cluster
Introduction
HashiCorp Vault is now being used as a centralized server for managing application properties, business logic configurations, and cronjob settings in Spring Boot projects. As its role becomes more critical, the need for a highly available infrastructure has become increasingly important.
Prerequisites
When setting up a Vault cluster, HashiCorp recommends using Vault’s integrated storage (Raft) for most use cases. This approach simplifies the setup by removing the need for external storage systems, making it easier to manage and maintain.
Raft Storage
By using Vault’s Integrated Storage (Raft) for encrypted data, Raft storage offers the following benefits:
- Simplifies Management: Raft is integrated into Vault, reducing the need for external storage setup.
- Supports High Availability: Offers built-in failover and multi-cluster replication.
- Improves Performance: Eliminates extra network requests by storing data directly within Vault.
- Eases Troubleshooting: Fewer components make diagnosing issues faster and simpler.
The Cluster Architecture
Overview
The following diagram shows the recommended architecture by HashiCorp for deploying a single Vault cluster with maximum resiliency:
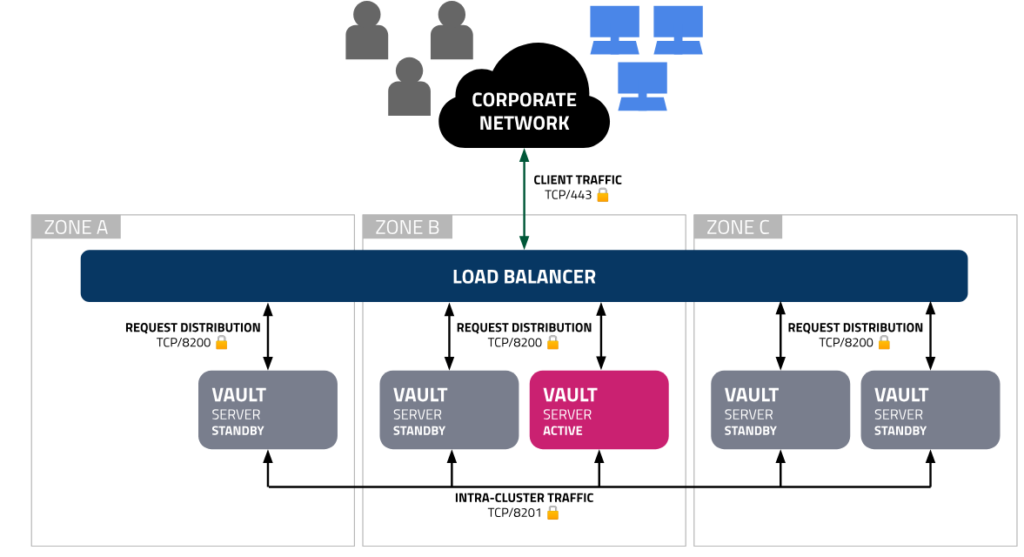
With five nodes in the Vault cluster, this architecture can withstand the loss of two nodes.
Vault operates in a high-availability (HA) cluster mode, where one node is designated as the active node and the remaining nodes serve as standby nodes. The active node handles all incoming read and write requests, while standby nodes are kept in sync and are ready to take over in case the active node fails.
Load Balancing in Vault OSS
In the Vault OSS (Open-source software) version, the role of standby nodes is limited. They do not handle requests independently and instead redirect any received requests to the active node.
Setting up a reverse proxy in front of Vault cluster could be challenging, as the redirection process can introduce inefficiencies if not managed properly:
- Round-Robin Load Balancing: While round-robin is a common load-balancing strategy, it is not optimal for Vault OSS. When using round-robin, requests may be sent to standby nodes, which will then redirect them to the active node. This introduces unnecessary network hops, increasing latency and degrading overall performance, and this is the case for any load balancing algorithm.
- Active Node Routing: For better performance in a Vault OSS cluster, it is recommended to configure the load balancer to identify the active node and route all traffic directly to it, as this avoids the redirection overhead.
Load Balancing in Vault Enterprise
Vault Enterprise introduces the concept of performance standby nodes, which can handle read requests, allowing for load distribution across multiple nodes. However, write requests must still be directed to the active node, as it remains responsible for managing all data changes within the cluster.
Our Implementation
Given the active/standby architecture of Vault, particularly in the OSS version, we have gone with using HA-Proxy Sever.
HA-Proxy can be configured to monitor the health of Vault nodes, specifically checking which node is active. By routing all traffic to the active node, HA-Proxy ensures that requests are handled efficiently without the delays caused by redirection from standby nodes.
The same functionality could be achieved with NGINX Plus or a community module for NGINX from GitHub, but we choose HA-Proxy because it has health check as a built-in feature.
HA Proxy Config:
global
log stdout format raw local0
maxconn 4096
user haproxy
group haproxy
defaults
log global
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
retries 3 # Reduced retries to avoid excessive retries in a short time
option redispatch # Try another server if the selected one fails
frontend vault
bind *:8200
mode http
default_backend vault_backend
backend vault_backend
mode http
option httpchk GET /v1/sys/health
http-check expect status 200
http-check expect rstring "\"standby\":false"
balance roundrobin
option allbackups
default-server inter 10s fall 50 rise 1 maxconn 200retries 3 # Retry up to 3 times before considering the server unavailable
timeout connect 2s # Timeout for establishing a connection
timeout server 10s # Timeout for completing a requestserver vault1 vault-raft1:8200 check inter 10s fall 50 rise 1
server vault2 vault-raft2:8200 check inter 10s fall 50 rise 1
server vault3 vault-raft3:8200 check inter 10s fall 50 rise 1
The main purpose of configuring HA-Proxy is to ensure that all client requests are directed to the active Vault node in an efficient and reliable manner. Here’s how it works:
- Active Node Detection: HA-Proxy continuously monitors the health of each Vault node by sending health check requests to the /v1/sys/health endpoint. It checks for a status of 200 and verifies that the node is not in standby mode (using the "standby":false condition). This allows HA-Proxy to identify which node is currently active and capable of handling requests.
- Routing Traffic: Once HA-Proxy identifies the active node, it routes all incoming traffic directly to this node, avoiding the inefficiencies and delays that would occur if requests were sent to standby nodes.
- Failover Handling: If the active node goes down, HA-Proxy automatically detects the failure through its health checks. It then reroutes traffic to the next available node that passes the health checks and is not in standby mode. This ensures continuous availability and minimizes downtime.
Conclusion
This approach allows for a clean separation of configurations across different clients and environments, making it easier to manage and update secrets as needed.
References
https://cloud.spring.io/spring-cloud-vault/reference/html/#vault.config.backends
https://developer.hashicorp.com/vault/docs/internals/high-availability
https://developer.hashicorp.com/vault/tutorials/raft/raft-reference-architecture
https://developer.hashicorp.com/vault/tutorials/raft/raft-storage
Also some community discussions about this topic: